
Introduction
The development of Artificial Intelligence is amazing. Within every few months, we observe the launch of smarter, efficient, and high-performance AI systems. These inventions do not happen by chance; they are inspired by innovations in architecture and optimization methods.One of the most powerful advancements behind this rapid evolution is DeepSeek MLA (Multi-Head Latent Attention).
When you have read about modern AI models such as DeepSeek V2 or DeepSeek V3, you might have found that there has been a conversation about:
- Faster response times
- Reduced computational cost
- Improved long-context handling
The core innovation enabling these improvements is MLA.
However, there’s a major issue:
Most explanations are overly technical
They rely on complex terminology (latent vectors, projections, KV cache)
Beginners struggle to understand the concept
That’s exactly why this guide exists.
This article simplifies everything—without losing depth.
What is DeepSeek MLA?
Definition
DeepSeek MLA (Multi-Head Latent Attention) is an advanced attention mechanism designed to make AI systems:
- Faster
- More efficient
- Less expensive
- Highly scalable
It optimizes how models process and store attention-related data.
Simple Explanation (For Beginners)
Instead of storing massive amounts of raw attention data for every token, MLA:
- Compresses the data
- Stores a compact representation (latent form)
- Reconstructs it when needed
In simple words:
It stores less data but keeps the same intelligence.
Real-Life Analogy
Think about your smartphone storage:
| Method | Example |
| Traditional AI | Stores full-resolution photos ???? |
| MLA | Stores compressed images and restores them when needed |
Result:
- Same visual experience
- Up to 90% less storage usage
Why DeepSeek Introduced MLA
Problem with Traditional Attention (MHA)
Before MLA, most AI models used Multi-Head Attention (MHA).
While powerful, it had serious drawbacks.
Major Challenges:
- Memory consumption increases rapidly
- KV cache becomes extremely large
- GPU resources become expensive
- Processing becomes slower
Real Problem in Simple Words
When an AI model reads long text:
- It stores everything
- Memory fills quickly
- Costs increase significantly
- Speed decreases drastically
This makes scaling AI systems extremely difficult.
MLA Solution
DeepSeek introduced MLA to solve this exact problem.
Core Idea
- Compress KV cache into latent representations
- Reduce memory usage dramatically
- Maintain near-identical performance
Final Outcome
AI models can now:
- Handle 128K+ tokens
- Process faster
- Operate at a lower cost
- Scale efficiently
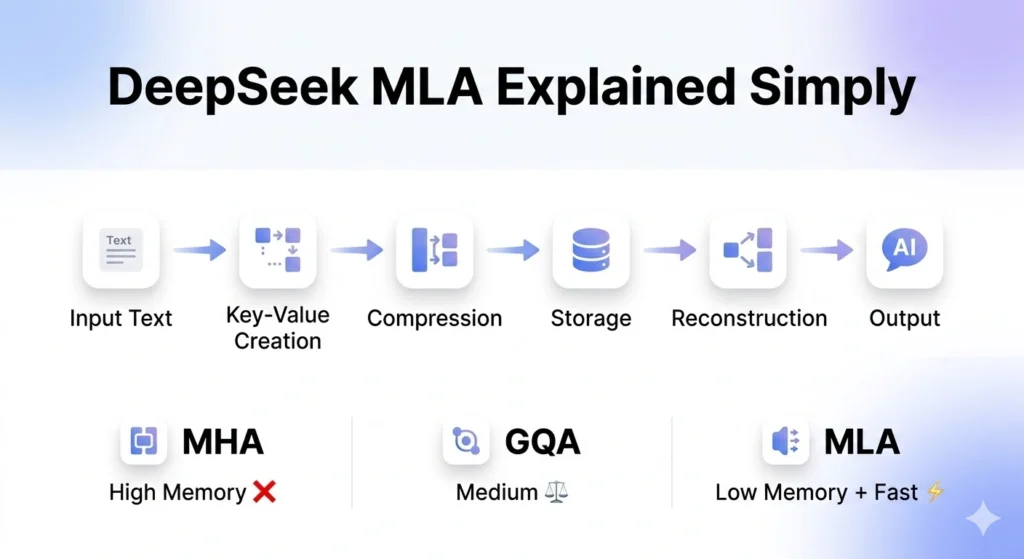
How DeepSeek MLA Works (Step-by-Step)
Let’s simplify the mechanism step by step.
Input Processing
The system receives text input and converts it into tokens.
Example:
“Hello world” → [Hello, world]
Key-Value Generation
Each token produces:
- Key (K)
- Value (V)
These elements help the model understand relationships between words.
Compression (Core Innovation)
Instead of storing full K and V data:
- MLA compresses the information
- Uses dimensionality reduction techniques
This is the most important step.
Efficient Storage
- Only compressed representations are stored
- Memory usage becomes significantly smaller
Reconstruction
When needed:
- Data is reconstructed from the latent space
- Information becomes usable again
Attention Computation
- The model performs attention calculations
- Output quality remains consistent
Process Summary Table
| Step | Action | Benefit |
| 1 | Tokenization | Converts text |
| 2 | KV creation | Prepares relationships |
| 3 | Compression | Reduces size |
| 4 | Storage | Saves memory |
| 5 | Reconstruction | Restores data |
| 6 | Attention | Maintains accuracy |
MLA vs MHA vs GQA (Complete Comparison)
This is a critical section for understanding differences.
Comparison Table
| Feature | MLA | MHA | GQA |
| Memory Usage | Very Low | Very High | Medium |
| Speed | Very Fast | Slow | Moderate |
| Efficiency | Highest | Low | Medium |
| Scalability | Excellent | Poor | Good |
| Cost | Low | High | Medium |
| Complexity | High | Low | Medium |
Detailed Breakdown
MHA (Multi-Head Attention)
- Stores complete KV cache
- High memory requirement
- Struggles with long sequences
Simple but inefficient
GQA (Grouped Query Attention)
- Shares KV across heads
- Reduces memory usage slightly
Improvement over MHA but still limited
MLA (Multi-Head Latent Attention)
- Compresses KV cache
- Highly optimized
- Designed for modern large-scale AI
Best overall performance
Final Verdict
MLA dominates in:
- Speed
- Efficiency
- Cost
- Scalability
Key Benefits of DeepSeek MLA
1. Massive Memory Reduction
- Up to 90% reduction
- Enables long-context processing
2. Faster Inference
- Less data = faster computation
- Improved response time
3. Lower Operational Cost
- Reduced GPU usage
- Lower infrastructure expenses
4. Enhanced Scalability
- Handles large datasets
- Supports long conversations
5. Environmental Impact
- Reduced computation
- Lower energy consumption
More sustainable AI systems
Real-World Impact of MLA
MLA is not just theoretical—it has real-world implications.
Developers
- Build high-performance applications
- Reduce backend costs
- Improve efficiency
AI Products
- More intelligent chatbots
- Longer conversation memory
- Better user experience
For Businesses
- Lower deployment costs
- Scalable AI infrastructure
- Enhanced customer support
Key Use Cases
- AI Assistants
- Document summarization
- Coding tools
- Real-time translation
- Long-form content generation
Limitations of DeepSeek MLA
No technology is perfect.
Drawbacks
- Slight accuracy reduction
- Complex implementation
- Requires optimization
- Reconstruction overhead
Pros vs Cons Summary
Advantages
- Highly efficient
- Fast processing
- Cost-effective
- Scalable
Disadvantages
- More complex than traditional methods
- Possible minor detail loss
- Requires expertise
MLA in DeepSeek V2 & V3
DeepSeek V2
- First implementation of MLA
- Significant performance improvements
DeepSeek V3
- Enhanced MLA architecture
- Combined with:
- Mixture of Experts (MoE)
- Low-precision computation
- Advanced training strategies
Result: Next-generation AI performance
Future of MLA Technology
The future of MLA looks extremely promising.
Upcoming Innovations
- Adaptive compression techniques
- Multimodal MLA (text, image, video)
- Further memory reduction
- Broader adoption
Prediction
MLA could become the Industry Standard for attention mechanisms.
Why MLA Matters for the Future of AI
Understanding MLA is crucial because:
- AI is moving toward efficiency
- Costs are becoming a major concern
- Long-context processing is the future
MLA solves all three challenges effectively.
FAQs
DeepSeek MLA is a method that compresses attention data to reduce memory usage while keeping AI performance high.
Because it uses less memory, runs faster, and costs less, while giving similar results.
Only slightly (usually less than 1%), which is negligible in most cases.
It is used in advanced AI models like DeepSeek V2 and V3.
Yes, it has strong potential due to its efficiency and scalability
Conclusion
One of the most impactful innovations of modern Artificial Intelligence is DeepSeek MLA.
Capturing huge amounts of data via conventional means is no longer necessary: MLA proposes a wiser and highly streamlined solution:
Compress → Store → Reconstruct
This simple yet powerful idea results in:
- Faster AI systems
- Lower operational cost
- Improved scalability
With the further development of AI, efficiency would be the most important aspect- and MLA is taking the lead in the change.










