
Introduction
Artificial intelligence continues to evolve at an Unprecedented velocity, with new models emerging each year that redefine computational understanding and generative capabilities. In this accelerating ecosystem, Meta’s Llama 4 family has become a significant milestone in the AI landscape, particularly spotlighting two prominent models: Llama 4 Maverick and Llama 4 Behemoth.
Although they belong to the same generative architecture lineage, these models are purpose-built with contrasting design philosophies and computational goals. Maverick is a production-oriented model optimized for deployment in real-world applications today, whereas Behemoth is a research-focused behemoth engineered to push the frontier of AI exploration.
In this comprehensive guide, we will dissect every aspect of, including:
- Architectural and parameter distinctions
- Benchmark evaluations
- Hardware and infrastructure requirements
- Practical deployment scenarios
- Comparative pros and cons
- Guidance on selecting the optimal model based on your use case
By the end of this discussion, you will have a clear understanding of:
- The differentiating factors between the two models
- Which model excels in specific computational tasks
- Practical and experimental applications
- The implications of active parameters and Mixture-of-Experts (MoE) architectures
- Strategic advice for developers, enterprises, and research teams
Let’s embark on a detailed exploration of these two cutting-edge AI models.
What Are Llama 4 Maverick and Llama 4 Behemoth?
Llama 4 Maverick Overview
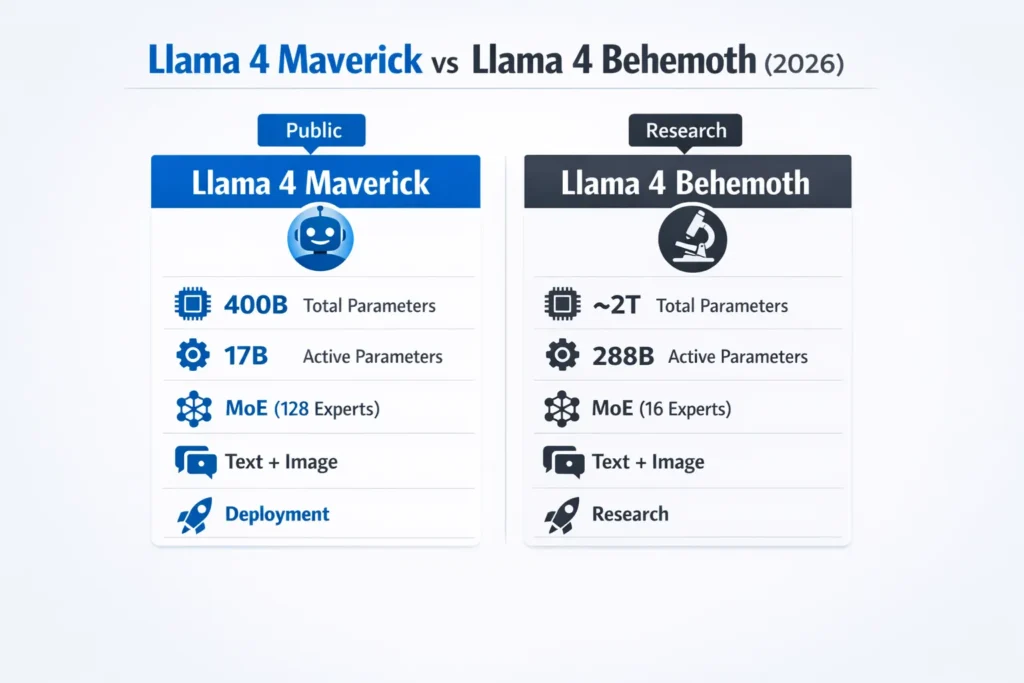
The Llama 4 Maverick model is a highly optimized AI system designed for practical, real-time usage. Released publicly in April 2025, Maverick leverages Meta’s Mixture-of-Experts (MoE) architecture to dynamically activate subsets of its neural components, enabling efficient reasoning and multimodal understanding without the computational overhead of the full model.
Core Features of Maverick
| Feature | Llama 4 Maverick |
| Release Date | April 2025 |
| Architecture | MoE with 128 experts |
| Total Parameters | 400 billion |
| Active Parameters | 17 billion |
| Multimodality | Yes (Text + Images) |
| Context Length | Up to 1 million tokens |
| Primary Applications | Coding, reasoning, AI assistants, multilingual tasks |
| Availability | Publicly accessible |
Design Philosophy: Maverick balances computational efficiency and accuracy. By selectively activating experts based on task requirements, it reduces unnecessary computation while Maintaining high performance across a broad spectrum of tasks, including code generation, advanced reasoning, and multimodal comprehension.
In natural language processing terminology, Maverick’s contextual embeddings and cross-modal attention layers allow it to effectively interpret sequential inputs and integrate visual semantics into text-driven outputs. Compared to contemporaries like GPT-4o and Gemini 2.0 Flash, Maverick demonstrates lower latency on standard inference tasks while retaining competitive accuracy.
Llama 4 Behemoth Overview
In stark contrast, Llama 4 Behemoth is a research-grade, experimental AI model still under internal development at Meta. With an unprecedented ~2 trillion parameters, Behemoth is engineered to tackle extreme reasoning, deep scientific modeling, and meta-learning tasks, serving as a “teacher” for downstream AI systems.
Core Features of Behemoth
| Feature | Llama 4 Behemoth |
| Release Status | In training (not publicly released) |
| Architecture | MoE with 16 experts |
| Total Parameters | ~2 trillion |
| Active Parameters | 288 billion |
| Multimodality | Yes |
| Primary Applications | Advanced STEM, research, and model training |
| Availability | Internal Meta testing only |
Research Objectives: Behemoth is not intended for immediate deployment. Its architecture is optimized for high-dimensional tensor operations, large-scale transformer attention, and knowledge distillation workflows. By training at this scale, Behemoth provides a blueprint for future AI systems capable of autonomous scientific reasoning and complex predictive modeling.
From a perspective, Behemoth’s sparse attention layers and massive parameter space enable deep representation learning, allowing it to capture nuanced patterns across textual, visual, and tabular datasets.
Side-by-Side Technical Specifications
To visualize the distinctions between Maverick and Behemoth, consider the following comparative table:
| Feature | Llama 4 Maverick | Llama 4 Behemoth |
| Total Parameters | 400B | ~2T |
| Active Parameters | 17B | 288B |
| Architecture | MoE (128 experts) | MoE (16 experts) |
| Availability | Public | In Training |
| Multimodality | Yes | Yes |
| Benchmark Strength | Coding, reasoning | STEM, model distillation |
| Hardware Requirements | Enterprise GPUs (H100 DGX) | Multi-node GPU Clusters |
| Best For | Practical deployment | Research & experimental AI |
Quick Explanation
- Total Parameters: Indicates the overall size and learning capacity of the model.
- Active Parameters: Subset of parameters engaged during a specific inference or task.
- MoE Architecture: The Mixture-of-Experts approach selectively activates specialized network segments, optimizing efficiency.
- Multimodality: Ability to process and integrate multiple types of inputs, e.g., text and images.
Core Differences Explained
Design Intent and Purpose
Maverick: Tailored for developers and enterprises requiring immediate AI deployment. It emphasizes efficiency, lower hardware overhead, and high reliability for production workflows.
Behemoth: Intended for large research labs with substantial computational infrastructure. It prioritizes experimentation, advanced STEM problem-solving, and training future AI models.
Performance & Benchmarks
While Behemoth’s public performance metrics are unavailable, internal testing reveals significant advantages in tasks requiring high-dimensional reasoning, complex mathematical modeling, and meta-learning.
| Task Type | Maverick Performance | Behemoth Expected |
| Coding | Excellent | Excellent |
| Reasoning | Strong | Superior |
| Math/Science | Good | Outstanding |
| Multimodal | Excellent | Excellent |
Implications: Maverick excels in semantic parsing, code synthesis, and context-aware text generation, whereas Behemoth can handle extremely long context windows and complex multi-step reasoning chains that may surpass standard transformer models.
Hardware & Infrastructure
- Maverick: Can operate efficiently on a single enterprise-grade GPU like NVIDIA H100 DGX, making it accessible for mid-size companies.
- Behemoth: Requires distributed GPU clusters with high-speed interconnects, limiting its use to large-scale research institutions.
Real-World Use Cases
The two models cater to different operational environments.
| Use Case | Better Model | Why |
| AI Chatbots & Assistants | Maverick | Easy deployment & strong reasoning |
| Code Generation | Maverick | Fast and accurate |
| Multilingual Apps | Maverick | Robust language embeddings |
| Large Scientific Modeling | Behemoth | Massive parameter capacity |
| Enterprise Research Labs | Behemoth | Designed for complex AI experiments |
| AI Model Distillation | Behemoth | Facilitates the training of other models |
Maverick Examples
- Coding assistants integrated into IDEs like Visual Studio
- Image-aware customer support chatbots
- Multilingual translation applications
Behemoth Examples
- Predicting complex molecular interactions or chemical reactions
- Generating meta-datasets for model pretraining
- Advanced reasoning simulations for AI research
Pros & Cons
Llama 4 Maverick
Pros:
- Publicly accessible and production-ready
- Strong coding and reasoning Capabilities
- Efficient use of hardware with MoE architecture
- Multimodal support for text and images
Cons:
- Requires expensive enterprise GPU infrastructure
- Less suitable for extreme STEM research tasks
- Benchmark debates within the community regarding comparative performance
Llama 4 Behemoth
Pros:
- Massive scale (~2 trillion parameters) for high-dimensional tasks
- Exceptional internal performance in math, science, and reasoning
- Acts as a “teacher” for smaller models
- Supports large-scale model distillation
Cons:
- Not publicly released yet
- Requires massive hardware clusters
- Only suitable for research labs and advanced experimental setups
Maverick vs Behemoth: Who Wins?
Availability
Winner: Maverick. Already Deployable and accessible to developers.
Real-World Performance
Winner: Maverick. Ideal for production applications in coding, reasoning, and multimodal tasks.
Long-Term Potential
Winner: Behemoth. Unparalleled potential for research and future AI development.
Final Verdict:
- Immediate Deployment: Choose Maverick for applications requiring robust AI today.
- Research & Future Innovation: Behemoth is worth monitoring for high-end AI experimentation.
FAQs
A: Llama 4 Behemoth is still under internal development and not publicly accessible. No official release date has been confirmed.
A: In many practical tasks, especially coding, reasoning, and multimodal understanding, Maverick performs comparably to top-tier AI systems like GPT‑4o and Gemini 2.0 Flash.
A: Maverick It is optimized for coding assistance, IDE integration, and real-time inference tasks.
A: Likely yes in the future, but it will primarily target research labs with high computational resources.
A: Maverick supports both textual and visual inputs, enabling cross-modal reasoning and generative workflows.
Conclusion
In the rapidly evolving landscape of artificial intelligence, Meta’s Llama 4 family exemplifies the spectrum of modern AI capabilities from immediately deployable systems to experimental research behemoths. Both Maverick and Behemoth are engineered with cutting-edge Mixture-of-Experts architectures, multimodal Processing, and massive parameter spaces, yet they serve fundamentally different purposes.
Llama 4 Maverick shines as a practical, production-ready AI. With 400 billion parameters and 17 billion active parameters, it excels in coding assistance, reasoning tasks, and multimodal workflows. Its compatibility with enterprise-grade GPUs like the NVIDIA H100 DGX makes it accessible to companies and developers looking to deploy high-performance AI applications today. Maverick’s efficiency, flexibility, and proven benchmarks make it the go-to choice for real-world AI solutions.










