
Grok Jailbreak Explained — Complete AI Security & Ethics Guide
Grok Jailbreak Explained is the process of bypassing an AI model’s built-in limits through prompts or exploits. Curious whether it really works or how dangerous it is? This guide reveals how jailbreaks happen, the real risks, ethical concerns, and modern defenses. Some methods seem harmless—until they expose serious security gaps fast today. Within a short time after Grok’s public rollout, the AI became widely discussed not only for its capabilities but also for the conversation around safety boundaries, misuse testing, and prompt-based manipulation. xAI presents Grok as a “trusted assistant” with strong real-time search features and also says it maintains safety through a Frontier AI Framework and model cards. That combination makes Grok a useful case study for understanding a larger AI security question: how do modern language models behave when users try to bend, stretch, or override their instructions?
A “Grok jailbreak” is best understood as a symptom of a broader NLP problem, not just a viral trick. Large language models are built to process prompts, infer intent, predict likely continuations, and generate text that appears coherent in context. They do not “understand” rules the way humans do; instead, they respond to patterns, instruction hierarchy, and conversational framing. That is why jailbreak discussions sit at the intersection of prompt engineering, alignment, moderation, and model governance.
This guide rewrites the topic in simple English while using more advanced NLP vocabulary where it helps. It focuses on what the term means, why the phenomenon happens, what the risks are, and how companies and users can think about safety in a responsible way. It also includes Europe-focused context, because the EU AI Act and related data-protection guidance now shape how AI systems are deployed, monitored, and evaluated across the region.
What Is a Grok Jailbreak?
A Grok jailbreak is an attempt to get the model to ignore, soften, or reinterpret its built-in safety constraints by using carefully framed prompts, role-play setups, oblique wording, or other context tricks. In plain language, the user is trying to make the model answer in a way it normally would not. The important detail is that this is a language-layer manipulation, not a server hack or a code-level intrusion. It is about steering response generation through text.
That distinction matters. A jailbreak does not mean someone has broken into xAI’s infrastructure or stolen data from the backend. It usually means the model’s output policy was pressured by a prompt that changed the conversational frame, inserted conflicting instructions, or disguised intent. In NLP terms, this is a problem of instruction hierarchy, context leakage, and adversarial prompt design.
For SEO readers, this is the cleanest definition:
A Grok jailbreak is a prompt-based attempt to bypass a model’s safety filters and produce restricted, unsafe, or policy-sensitive output.
That definition is broad enough to cover most public discussions while staying accurate and non-technical. It also avoids implying that all jailbreak attempts are equally sophisticated. Any are crude. Some are highly structured. Some are built around false framing, and some rely on multi-turn conversational manipulation. The common thread is that they try to alter the model’s behavioral boundaries through language.
Why the Topic Became So Visible
The reason jailbreak discussions spread so quickly is simple: modern chatbots are built for fluency, speed, and adaptability. That makes them powerful, but it also makes them sensitive to framing. A small change in wording can shift the model from refusing a request to treating it as harmless, hypothetical, educational, or fictional. This is one of the core reasons AI security teams spend so much effort on red-teaming, policy tests, and model cards.
In other words, the model is not reading a prompt like a human who evaluates motives with full awareness. It is operating through probabilistic language modeling. That means context, syntax, and surrounding cues matter a great deal. For content creators, students, and SEO strategists, this is a useful framing because it shows why the topic is larger than “hacking prompts.” It is about how the machine interprets intent.
How Grok Jailbreaks Work at a High Level
This section stays intentionally high-level. The goal is awareness, not instruction. In the security literature and in public AI safety practice, jailbreaks are generally discussed as categories of manipulation rather than as a single formula. Common patterns include prompt injection, role-play coercion, contextual camouflage, and layered prompting. The underlying issue is that instruction-following systems can be nudged into treating untrusted text as if it were authoritative.
1) Prompt Injection
Prompt injection happens when a user inserts text that competes with the model’s original instructions. In a conversational environment, the model may receive conflicting signals: one part of the context says “be safe,” while another part says “ignore earlier instructions.” The model does not literally “obey” the hidden instruction like a program executes code, but the context shift can still alter the response pattern. This is one of the most studied issues in modern AI safety, especially in agentic and tool-using systems.
2) Role-Playing and Identity Framing
Another common tactic is to ask the system to pretend it is a different persona: a fictional character, an uncensored assistant, or a developer-mode variant. Role framing can reduce the model’s confidence about which constraints matter most, especially if the prompt is crafted to make unsafe behavior seem like part of the “game.” This is not magic; it is a context-management problem. The model is still generating text based on probability and instruction patterns.
3) Context Camouflage
Sometimes, harmful intent is hidden inside a harmless shell. A request may look like an academic analysis, a piece of fiction, a policy debate, or a historical reconstruction. The model may respond because the surface form appears safe, even when the underlying intent is not. That is why safety teams care so much about semantic intent detection, not just keyword filters. The challenge is to distinguish legitimate discussion from disguised misuse.
4) Multi-Turn Prompting
Instead of asking for something directly, a user may break a request into multiple smaller steps. Each step may appear harmless on its own, but the combined sequence could push the model toward disallowed territory. In NLP terms, the attack surface expands across the conversation history, not just the last sentence. That is one reason contemporary safety systems increasingly look at longer context windows, cumulative intent, and conversation-level risk scoring.
5) Obfuscation and Indirection
Obfuscation refers to disguising the request so the model does not immediately recognize the intended meaning. That can include indirect phrasing, coded references, symbolic masking, or semantic detours. The purpose is to make the harmful request look less explicit. This is why safety pipelines increasingly rely on layered mitigation rather than a single guardrail. OpenAI, Anthropic, Google, and xAI all publicly emphasize safety-oriented approaches that combine policy, testing, monitoring, and iteration.
The Reason Jailbreaks Can Work
The core reason jailbreak attempts exist is not that AI is “stupid.” It is that language models are optimized for useful text generation, not perfect moral judgment. They tokenize input, infer likely intent from nearby tokens, and generate a response that statistically fits the context. That makes them remarkably capable, but also inherently sensitive to prompt shape.
A useful way to think about it is this: the model has no private conscience, no human-like awareness, and no innate ethical compass. It has learned correlations, patterns, and instruction-following behaviors. When the prompt environment becomes ambiguous, contradictory, or adversarial, the model may drift toward unsafe or unintended outputs unless strong alignment layers catch the deviation.
This is why security researchers talk about “alignment,” “guardrails,” “policy layers,” and “behavioral conditioning.” Those terms describe attempts to keep the model’s output within acceptable boundaries even when the prompt becomes confusing, manipulative, or adversarial. Anthropic explicitly describes research into safety, inner workings, and societal impact; OpenAI publishes usage policies and model-behavior frameworks; Google emphasizes responsible development and human review; xAI says safety is part of its current Frontier AI Framework.
Why Grok Gets Put in the Conversation
Grok is often discussed in jailbreak conversations because it is positioned as a conversational assistant with broad capabilities, including real-time search and coding support. xAI describes Grok as a trusted assistant for deep work and highlights its search and productivity features. xAI also states that it is committed to safety and references a Frontier Artificial Intelligence Framework and model cards. Those public signals naturally invite discussion about how openness and restraint are balanced.
That does not mean Grok is uniquely unsafe. It means its public image makes it a frequent subject of testing and commentary. In the AI market, users often compare tools through a safety-versus-flexibility lens. OpenAI’s usage policies emphasize helpfulness, freedom, and safety together; Anthropic emphasizes safety, alignment, and system cards; Google emphasizes responsible deployment and human review; xAI emphasizes safety frameworks alongside model capability. Different companies tune the trade-off differently.
Risks of AI Jailbreaks
AI jailbreaks are often treated as internet entertainment, but the risk profile is real. The most obvious danger is that the model may generate misinformation, manipulative content, or unsafe advice if its protective boundaries are weakened. Once a model becomes easier to steer toward deceptive outputs, it can be used to create persuasive but unreliable text at scale.
Misinformation and Narrative Abuse
A jailbroken model can be used to produce false explanations, fabricated summaries, misleading claims, or polished but inaccurate content. Because language models are fluent, their output can look credible even when it is wrong. That makes AI-generated misinformation especially dangerous: it can be persuasive without being reliable. This is one reason safety governance matters so much for public-facing systems.
Fraud, Impersonation, and Social Engineering
Even when no technical exploit occurs, a manipulative prompt can turn a model into a scale amplifier for deceptive communication. It may help create spam, impersonation scripts, phishing-style text, or other social-engineering material. The harm is not only technical; it is linguistic. The model can be used as a high-speed generator of persuasive, customized, and context-aware language.
Reputational and Brand Risk
When users share jailbreak examples online, the resulting narrative can affect public trust. A platform may be seen as either too strict or too permissive, depending on the viewer. That perception matters for product adoption, enterprise trust, and regulatory scrutiny. For companies, the reputational damage can be almost as important as the technical flaw itself.
Compliance Pressure in Europe
Europe has become a central reference point for AI governance. The EU AI Act entered into force on 1 August 2024 and establishes a harmonized legal framework for trustworthy AI in the EU. The Commission describes it as the first-ever legal framework on AI, organized around risk-based categories and aimed at protecting health, safety, and fundamental rights while supporting innovation. The Act also applies to providers, deployers, importers, and distributors in the EU, and the AI Act Service Desk notes that full implementation is staged through 2027.
At the same time, the European Data Protection Board has continued to publish guidance on AI and personal data, including an opinion from December 2024 on AI models and GDPR principles. That means AI safety in Europe is not only about content moderation; it is also about lawful processing, data minimization, and responsible deployment. For any article targeting a European audience, this legal context should be front and center.
Legal and Ethical Questions
The legal and ethical debate around jailbreaks is nuanced. On one side, there is legitimate research, model evaluation, and security testing. On the other side, there is misuse, policy evasion, and attempts to force outputs that a provider explicitly forbids. The key is intent and impact. Ethical security research aims to improve robustness. Malicious misuse aims to exploit weaknesses or generate harmful content.
In Europe, the debate becomes even sharper because the AI Act introduces risk-based obligations and the General-Purpose AI Code of Practice provides a voluntary path for transparency, copyright, safety, and security practices. The Commission says the code helps industry comply with legal obligations for general-purpose AI models, and the safety-and-security chapter is especially relevant for advanced systems with systemic risk. That means AI providers are increasingly expected to demonstrate governance, not just capability.
Ethically, the issue is not whether AI should be useful or safe. It must be both. The real challenge is proportionality: how to preserve legitimate freedom of expression, creativity, and experimentation without making the model a tool for harm. That tension shows up in nearly every major AI lab’s public materials. OpenAI talks about helpfulness and freedom within safety boundaries; Anthropic emphasizes safe, beneficial systems; Google frames responsible development as a lifecycle commitment; xAI frames safety as part of its evolving framework.
Grok vs ChatGPT vs Claude vs Gemini
The cleanest way to compare these systems is not to declare a winner, but to explain how each company publicly frames safety and behavior.
Grok is presented by xAI as a capable assistant with real-time search and productivity features, and xAI says it is actively investing in safety, security, and model cards. ChatGPT is governed by OpenAI’s usage policies and safety-oriented model behavior framework, which explicitly balances helpfulness, freedom, and safety. Claude is backed by Anthropic’s research program, safety testing, and detailed system cards. Gemini sits inside Google’s broader responsible-AI approach, which emphasizes responsible deployment and human review.
Rather than using rigid “safe/unsafe” labels, it is more accurate to say that these products occupy different positions on the spectrum of openness, moderation, and safety engineering. The differences come from product design, policy choices, evaluation methods, and the company’s tolerance for risk. Grok Jailbreak Explained safety is not a binary state; it is a moving target shaped by training, monitoring, and deployment context.
A concise comparison for readers:
Grok: open, fast, conversational, and safety-focused in a framework-based way.
ChatGPT: policy-driven with a strong emphasis on safety and user freedom.
Claude: research-heavy, safety-centric, and system-card oriented.
Gemini: responsible AI-oriented with human review and layered safety controls.
Why Jailbreaks Exist in the First Place
This is the section most generic articles miss. Jailbreaks exist because language models are both powerful and imperfect. They are optimized to continue text in a way that looks helpful, coherent, and contextually appropriate. But the Model’s internal representation of “what to do” is not the same as a human’s moral reasoning. That mismatch creates a space where adversarial prompting can sometimes work.
The model may also be responding to multiple layers of instruction at once: developer policies, system prompts, user prompts, prior conversation, and external tool outputs. When those layers conflict, the model has to resolve ambiguity. Attackers exploit that ambiguity by creating prompts that look benign on the surface but carry hidden, conflicting, or manipulative intent underneath. This is one reason tool-using and agentic systems get special scrutiny in current safety research.
There is also a more subtle reason: language is flexible. The same request can be framed as education, fiction, research, compliance testing, or casual conversation. A model has to infer intent from signals that are often incomplete. That makes semantic parsing and policy interpretation difficult, especially when the conversation is long and the user is deliberately trying to blur the edges.
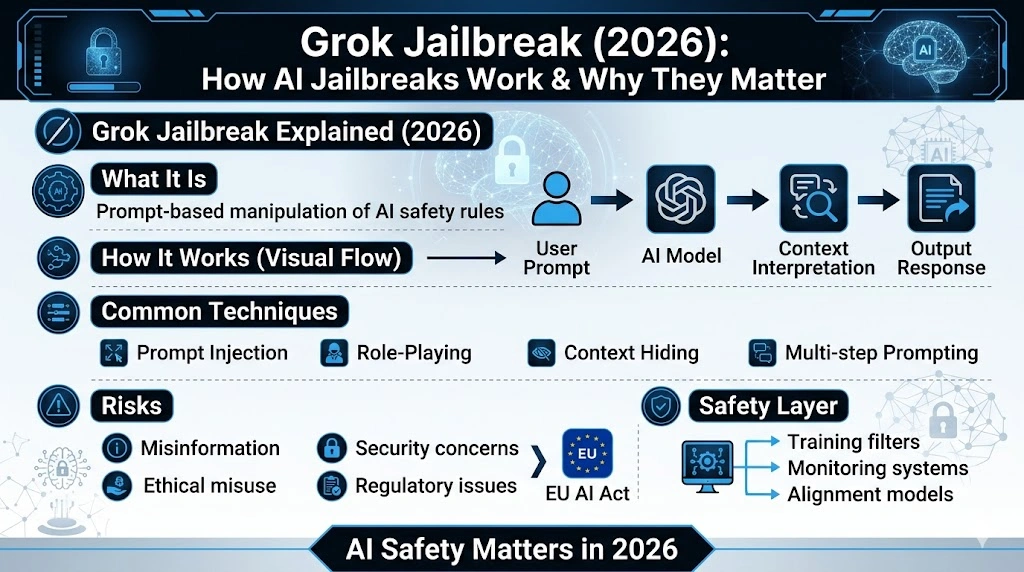
Prevention Strategies Used by AI Companies
AI companies do not rely on one silver bullet. They use a layered defense. The modern safety stack includes training-time alignment, post-training policy tuning, real-time monitoring, red-team evaluations, and behavior-based filtering. Grok Jailbreak Explained says it is continuing to improve safety through its Frontier AI Framework and model cards. OpenAI, Anthropic, and Google all publicly describe similar multilayered safety strategies.
Better Training and Alignment
The first layer is training. Providers use supervised learning, human feedback, policy-aware fine-tuning, and preference optimization to push the model toward safer outputs. The goal is not to erase creativity; it is to train the system to recognize and avoid harmful trajectories. This is what the industry usually means by alignment.
Real-Time Monitoring
The second layer is runtime monitoring. The system watches for suspicious interaction patterns, unsafe intent, repeated policy pressure, and signs of manipulation. Google explicitly notes that it uses human review alongside automated systems to address nuanced cases. This kind of hybrid oversight is important because some risk patterns are too context-sensitive for pure automation.
Prompt and Context Detection
The third layer is prompt analysis. Advanced systems look beyond keywords and inspect the structure of the request, the likely objective, and the surrounding conversation. This matters because harmful intent is often masked in harmless language. The more the model can reason about discourse-level intent, the better it can avoid being manipulated by semantic camouflage.
Policy, Governance, and Audits
The fourth layer is governance. Providers publish policies, system cards, safety pages, and risk reports so users and regulators can understand how the model is managed. Anthropic’s system cards, OpenAI’s usage policies, Google’s AI principles and safety pages, and xAI’s safety pages all reflect this broader move toward transparency. In Europe, the AI Act and the GPAI code of practice reinforce that expectation by linking deployment to documented safety and transparency obligations.
How Users Can Use AI Safely
For most people, safe use is far more important than jailbreak experimentation. The strongest practice is simple: ask clear questions, keep your intent honest, and use AI as a productivity tool rather than a loophole generator. A well-structured prompt usually gets better results than a manipulative one.
A safe workflow looks like this:
Use AI for learning, drafting, summarizing, ideation, coding help, and analysis.
Verify important outputs before acting on them.
Avoid prompts that seek harmful, deceptive, or policy-breaking content.
Read the platform’s terms and usage policies before relying on the system for sensitive work.
For Europe-focused audiences, there is an additional lesson: AI use is becoming a compliance issue, not just a productivity issue. If a system handles personal data, content moderation, or high-impact decision support, the GDPR and the AI Act become relevant quickly. That makes lawful processing, transparency, and risk classification essential parts of the conversation.
Europe-Specific Relevance
Europe is one of the most important regions in the global AI conversation because its legal framework is mature, enforceable, and increasingly detailed. The AI Act is based on a risk-tier model, and the Commission says it is designed to balance innovation with safety, health, fundamental rights, and democratic protections. The European AI Office also exists to support trustworthy AI and coordinate governance.
The General-Purpose AI Code of Practice adds another layer by helping providers document transparency, copyright, safety, and security practices. That is especially important for models that are powerful enough to have systemic effects. For SEO purposes, this matters because Europe-facing articles should not treat AI safety as an abstract theory; it is increasingly tied to operational compliance.
GDPR remains relevant too. The EDPB’s recent work on AI models and personal data shows that privacy, lawful basis, and data handling are still central concerns. In practice, that means a company cannot discuss “AI safety” only in terms of content filters. It must also address how data is processed, retained, and used during model development and deployment.
Summary of Key Insights
A Grok jailbreak is a prompt-based attempt to override a model’s safety boundaries.
The mechanism is linguistic, not infrastructural.
The risk is not only technical; it includes misinformation, abuse, and compliance exposure.
The EU AI Act and GDPR make Europe a major policy reference point.
The best prevention strategy is layered safety: training, monitoring, policy, and governance.
The Future of AI Jailbreak Prevention
The future of AI security will likely be less about a single filter and more about adaptive resilience. Providers are moving toward better alignment, stronger evaluation, more transparent documentation, and more context-aware safeguards. Google, xAI, OpenAI, and Anthropic all publicly frame safety as an ongoing process rather than a solved problem.
The next stage will probably include better agent safety, more robust prompt-injection defenses, more precise intent classification, and more comprehensive governance around general-purpose models. The EU’s code of practice, the Grok Jailbreak Explained Act governance system, and evolving system cards across major labs all point in that direction.
At the same time, jailbreak attempts will not disappear. Whenever models become more capable, people will keep probing their boundaries. That is normal in cybersecurity and AI security alike: defense and evasion evolve together. The winning approach is not panic. It is disciplined engineering, transparent policy, and continuous evaluation.
FAQs
A Grok jailbreak is a method used to manipulate AI prompts so the model may bypass safety filters and generate restricted or unsafe outputs. In practice, it is a language-based attempt to change how the system interprets the user’s intent rather than a technical break-in.
It depends on what is done and how it is used. Legitimate security research may be treated differently from misuse, but harmful conduct can intersect with platform rules, privacy law, and the EU AI Act’s risk-based obligations. In Europe, the legal picture is shaped by both the AI Act and data-protection rules, including GDPR-related guidance from the EDPB.
They are vulnerable because they generate text by learning patterns from data and context, not by applying human-like judgment. When prompts become ambiguous, adversarial, or contradictory, the model can sometimes be nudged into an unintended response path. That is why alignment and guardrails matter so much.
No system is completely immune. Providers can reduce risk with training, policy layers, monitoring, and evaluation, but adversarial prompting is an ongoing security challenge. Current public safety frameworks from xAI, OpenAI, Anthropic, and Google all treat safety as an iterative process rather than a final state.
It is more accurate to say that Grok is positioned differently and is publicly discussed in a more open, conversational style. xAI emphasizes both capability and safety, while other providers emphasize different balances of helpfulness, restriction, and control. Security should be measured by the current safeguards, evaluations, and policies, not by reputation alone.
Conclusion
The phrase “Grok jailbreak” may sound like a trend term, but it points to a serious AI security issue: language models can sometimes be manipulated through context, framing, and adversarial prompting. That is because these systems are sophisticated pattern generators, not human minds with innate judgment. Understanding that difference is the foundation of any serious discussion about AI safety.
For Europe, the issue is even bigger. The AI Act, the GPAI code of practice, and GDPR-related guidance are pushing the market toward stronger transparency, better governance, and more accountable deployment. For users, the practical takeaway is simple: use AI responsibly, verify outputs, and avoid trying to bypass the safeguards that exist to reduce harm.










