
Introduction
Artificial intelligence is Advancing at an extraordinary pace. Every year, new AI systems emerge that push the boundaries of what machines can understand, generate, and automate. From natural language processing to complex reasoning and programming, modern AI models are transforming industries across the world.
Among the newest and most discussed innovations in the AI ecosystem is DeepSeek V3.2-Exp. This experimental large language model has attracted widespread attention because of its focus on something extremely critical in modern artificial intelligence development: efficiency and scalability.
Many cutting-edge AI systems today are powerful but also incredibly expensive to operate. Running large models often requires enormous computational resources, specialized hardware, and massive energy consumption. DeepSeek aims to address this challenge by designing models that deliver competitive performance while dramatically reducing the computing requirements needed to operate them.
Because of this approach, DeepSeek V3.2-Exp is becoming increasingly appealing to developers, startups, enterprises, and researchers who want high-performance AI capabilities without the massive infrastructure costs typically associated with frontier models.
The model introduces several important technical innovations, including:
- DeepSeek Sparse Attention (DSA)
- Mixture-of-Experts (MoE) architecture
- Multi-Latent Attention (MLA)
- Extremely large context windows
- Efficient inference pipelines
These technologies enable the model to process extremely long documents, solve complex reasoning tasks, and assist with software development workflows while maintaining relatively low operational costs.
In this comprehensive DeepSeek V.2-Exp guide, you will learn:
- What DeepSeek V3.2-Exp is
- How the model architecture works
- Benchmark results and performance metrics
- Comparisons with GPT, Claude, and Gemini models
- Pricing and infrastructure considerations
- Real-world applications and use cases
- Limitations and future development trends
Whether you are an AI engineer, startup founder, academic researcher, product manager, or simply an enthusiast interested in artificial intelligence, this detailed guide will help you understand why DeepSeek V3.2-Exp is becoming an important player in the rapidly evolving AI landscape.
What Is DeepSeek V3.2-Exp?
DeepSeek V3.2-Exp is an experimental large language model developed by DeepSeek AI to enhance long-context understanding, reasoning performance, and computational efficiency.
The system builds upon earlier models from the DeepSeek family and incorporates several architectural improvements designed to scale large neural networks more effectively.
Unlike many AI systems that primarily attempt to increase raw model intelligence by simply adding more parameters, DeepSeek follows a slightly different design philosophy. Instead of focusing only on scale, the developers emphasize performance efficiency — meaning how much capability a model can deliver relative to its computational cost.
This approach can dramatically lower operational expenses for companies building AI-powered products.
For example, many AI services must process millions of tokens every day. If the cost per token is high, running these systems becomes financially unsustainable. DeepSeek attempts to solve this problem by optimizing architecture, memory usage, and attention mechanisms.
As a result, the model is capable of delivering strong performance across multiple domains while maintaining lower inference costs compared with many competing models.
Key Facts About DeepSeek V3.2-Exp
| Feature | Details |
| Release | Experimental model introduced in 2025 |
| Architecture | Mixture-of-Experts (MoE) |
| Context Window | ~200K+ tokens |
| Total Parameters | ~685 billion parameters |
| Key Innovation | DeepSeek Sparse Attention |
| Core Focus | Efficiency, reasoning, coding |
These attributes make DeepSeek V3.2-Exp particularly valuable for several high-demand applications, such as:
- Large document processing
- Software development support
- Research and data analysis
- Enterprise knowledge management
- AI automation tools
The model’s focus on efficiency optimization is what truly differentiates it from many other frontier AI systems.
Evolution of DeepSeek AI Models
To fully understand DeepSeek V3.2-Exp, it is helpful to examine how the DeepSeek model family has progressed over time. Each generation introduced improvements in architecture, performance, and scalability.
DeepSeek V3
The release of DeepSeek V3 marked a major milestone for the company.
This model introduced a powerful, large-scale transformer architecture capable of competing with many well-known AI systems in multiple benchmarks.
Key characteristics included:
- Large transformer-based neural network
- Strong multilingual understanding
- Competitive performance on knowledge benchmarks
- High-quality programming capabilities
- Advanced language comprehension
The release positioned DeepSeek as a serious competitor in the artificial intelligence industry.
DeepSeek V3.1
The next iteration, DeepSeek V3.1, focused on improving reasoning capabilities and computational scalability.
Important improvements included:
- Expanded context windows
- Better reasoning accuracy
- Hybrid inference techniques
- More efficient model optimization
Because of these enhancements, many developers started integrating DeepSeek models into research tools and AI applications.
DeepSeek V3.2-Exp
The latest experimental release takes a slightly different strategic direction.
Instead of focusing exclusively on increasing intelligence metrics, the model emphasizes efficiency engineering and long-context scalability.
Key objectives include:
- Lower computational overhead
- Faster inference speeds
- Efficient attention algorithms
- Enhanced long-context reasoning
These improvements make the model particularly attractive for large-scale deployments and enterprise AI systems.
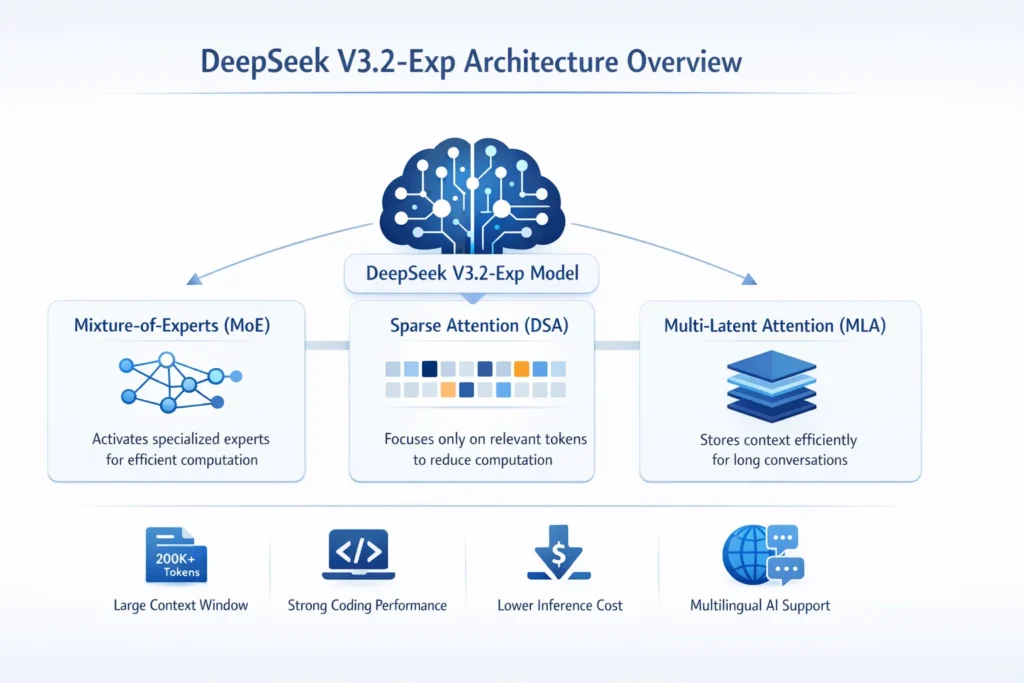
DeepSeek V3.2-Exp Architecture Explained
The architecture behind DeepSeek V3.2-Exp is what makes the model particularly innovative.
Modern AI models require enormous computational resources. However, DeepSeek introduces several techniques that reduce the overall computational burden.
Three primary technologies power the system.
Mixture-of-Experts (MoE) Architecture
The Mixture-of-Experts architecture is becoming increasingly common in modern large language models.
Instead of activating the entire neural network for every request, the model activates only a subset of specialized components called experts.
Each expert is trained to handle particular types of tasks.
Examples include:
- mathematical reasoning
- programming logic
- language understanding
- contextual interpretation
When a prompt enters the model, a routing algorithm determines which experts should be activated.
Benefits of MoE Architecture
- Lower computational consumption
- Faster inference latency
- Higher scalability potential
- Improved parameter utilization
For instance, a 600-billion-parameter model might only activate 30-50 billion parameters during inference.
This dramatically reduces the amount of computation required while maintaining strong performance levels.
This is why MoE architectures are increasingly used in frontier AI models.
Multi-Latent Attention (MLA)
Another important advancement is Multi-Latent Attention (MLA).
Traditional transformer models store contextual information using key-value memory structures. However, as context size grows, these memory structures become extremely large.
MLA optimizes this process by compressing contextual data into latent representations.
Benefits of MLA
- Better memory efficiency
- Improved long-conversation comprehension
- Scalable inference architecture
This allows the model to maintain contextual awareness across very long conversations and documents.
Key Features of DeepSeek V3.2-Exp
Now, let’s examine some of the most important capabilities that make the model powerful.
Massive Context Window
One of the most notable features of DeepSeek V3.2-Exp is its enormous context window.
The model supports approximately 200,000+ tokens, enabling it to process extremely large inputs.
Examples include:
- entire books
- multi-file codebases
- academic research papers
- lengthy legal documents
Very few AI models currently support context windows of this size while remaining efficient
Reduced Inference Costs
Running large language models can be extremely expensive.
DeepSeek focuses heavily on reducing these operational costs.
Techniques used include:
- sparse attention algorithms
- Mixture-of-Experts routing
- optimized inference pipelines
Because of these improvements, developers can run large AI systems at significantly lower cost.
Powerful Coding Capabilities
DeepSeek models are widely recognized for their programming performance.
Developers Frequently use them for:
- code generation
- debugging support
- documentation writing
- AI coding assistants
In many programming benchmarks, DeepSeek models demonstrate competitive performance compared with major AI systems.
Multilingual Understanding
DeepSeek V3.2-Exp also offers strong multilingual capabilities.
The model supports more than 100 languages, enabling global applications such as:
- multilingual chatbots
- translation systems
- cross-language research tools
Developer-Friendly Ecosystem
Another important advantage is the developer-focused ecosystem.
Many AI companies restrict access to their models through tightly controlled platforms.
DeepSeek aims to provide a more flexible environment.
Advantages include:
- developer APIs
- commercial deployment options
- flexible integration
These factors have helped the model gain rapid popularity within the developer community.
Benchmarks and Performance
Benchmarks help evaluate how well AI models perform across different tasks.
DeepSeek V3.2-Exp demonstrates strong results across several categories.
| Benchmark | Score | Focus |
| MMLU-Pro | 85+ | Knowledge reasoning |
| AIME | 89 | Mathematical reasoning |
| SimpleQA | 97 | Question answering |
| Codeforces | 2100+ | Programming |
These results indicate strong capabilities in areas such as:
- mathematics
- logical reasoning
- programming
- general knowledge
However, benchmarks alone do not always reflect real-world performance. Results often depend on datasets, prompts, and application design.
DeepSeek V3.2-Exp vs Other AI Models
Many users want to understand how DeepSeek compares with other leading AI systems.
Major competitors include:
- GPT‑4
- Claude 3
- Gemini
Comparison Overview
| Model | Strengths | Weaknesses |
| DeepSeek V3.2-Exp | Efficient, long context, strong coding | Experimental |
| GPT-4 | Excellent reasoning | Higher cost |
| Claude 3 | Strong writing abilities | Limited ecosystem |
| Gemini | Multimodal capabilities | Platform restrictions |
Each system follows a different design philosophy.
The best choice depends on the specific application and infrastructure requirements.
DeepSeek V3.2-Exp Pricing
One major reason developers choose DeepSeek is its competitive pricing structure.
Example pricing model:
| Token Type | Cost per Million Tokens |
| Input Tokens | ~$0.27 |
| Output Tokens | ~$0.41 |
Compared with many frontier AI APIs, this pricing is extremely affordable.
Lower pricing enables companies to:
- scale AI applications
- process massive datasets
- deploy autonomous AI agents
Real-World Use Cases
DeepSeek V3.2-Exp supports many real-world applications.
AI Coding Assistants
Developers integrate the model into:
- IDE plugins
- code generation tools
- debugging assistants
Research and Knowledge Analysis
The large context window allows the model to analyze entire research papers simultaneously.
Applications include:
- Literature review automation
- research summarization
- scientific data analysis
AI Agents
Modern AI systems increasingly rely on autonomous agents.
DeepSeek works well for:
- tool-using agents
- workflow automation
- browsing assistants
Enterprise Knowledge Systems
Businesses use AI for internal information management.
Examples include:
- document search systems
- employee knowledge bases
- customer support AI
Legal and Financial Analysis
Many industries rely on analyzing Extremely large documents.
DeepSeek helps with:
- contract analysis
- legal document review
- financial report summarization
Advantages and Limitations
Like every AI system, DeepSeek V3.2-Exp has strengths and weaknesses.
Pros
- extremely large context window
- efficient inference costs
- strong coding performance
- developer-friendly ecosystem
- competitive benchmark scores
Cons
- experimental model
- smaller ecosystem compared with larger platforms
- Reasoning may lag specialized models
- limited multimodal capabilities
Understanding these trade-offs helps organizations select the most appropriate AI system.
Who Should Use DeepSeek V3.2-Exp?
This model is particularly useful for several groups.
Developers
Developers benefit from lower API costs and strong coding assistance.
Startups
Startups can deploy powerful AI systems without massive infrastructure expenses.
Research Teams
Researchers benefit from long-context document analysis.
Enterprises
Large companies can use the model for internal AI assistants, automation systems, and document analysis.
Future of DeepSeek AI
The rapid progress of DeepSeek suggests that even more powerful models may appear in the near future.
Experts expect future systems to focus on:
- improved reasoning abilities
- multimodal understanding
- further efficiency improvements
If development continues at the current pace, DeepSeek could become one of the most influential AI companies in the global technology industry.
FAQs
A: DeepSeek V3.2-Exp is an experimental large language model designed to improve efficiency, long-context processing, and coding performance.
A: Its main innovation is DeepSeek Sparse Attention, which reduces computational complexity and allows efficient long-context processing.
A: The model supports approximately 200K+ tokens, enabling it to analyze very large documents.
A: DeepSeek models are generally more open and developer-friendly than many proprietary AI systems, though deployment options vary.
A: It depends on the use case.
DeepSeek is often cheaper and better for long-context workloads, while GPT models may perform better in integrated ecosystems.
Conclusion
DeepSeek V3.2-Exp represents an important step forward in the evolution of modern artificial intelligence systems. Instead of focusing solely on increasing model size or raw computational power, the developers prioritized efficiency, scalability, and practical deployment.
Through innovations such as Mixture-of-Experts architecture, DeepSeek Sparse Attention, and Multi-Latent Attention, the model demonstrates how large language models can process extremely long contexts while keeping Inference costs manageable. These architectural improvements allow the system to analyze large datasets, understand complex documents, and assist with programming tasks without requiring excessive computing resources.










