Introduction
Open-source AI has changed Dramatically over the last two years. At first, bigger parameter counts dominated conversations. Then developers realized something important: Large models do not always mean higher cost. That shift is exactly why DeepSeek-MoE and Meta’s Llama 3 Series became two of the most discussed open-weight ecosystems. One side prioritizes sparse activation and efficiency. The other focuses on predictable dense computation and broad ecosystem support. If you are choosing an AI stack in 2026, benchmarks alone are not enough.
You need to know:
- Which model is cheaper to run
- Which scales better
- Which writes better code
- Which performs best for startups
- Which handles long-context workflows
- Which is easier to deploy
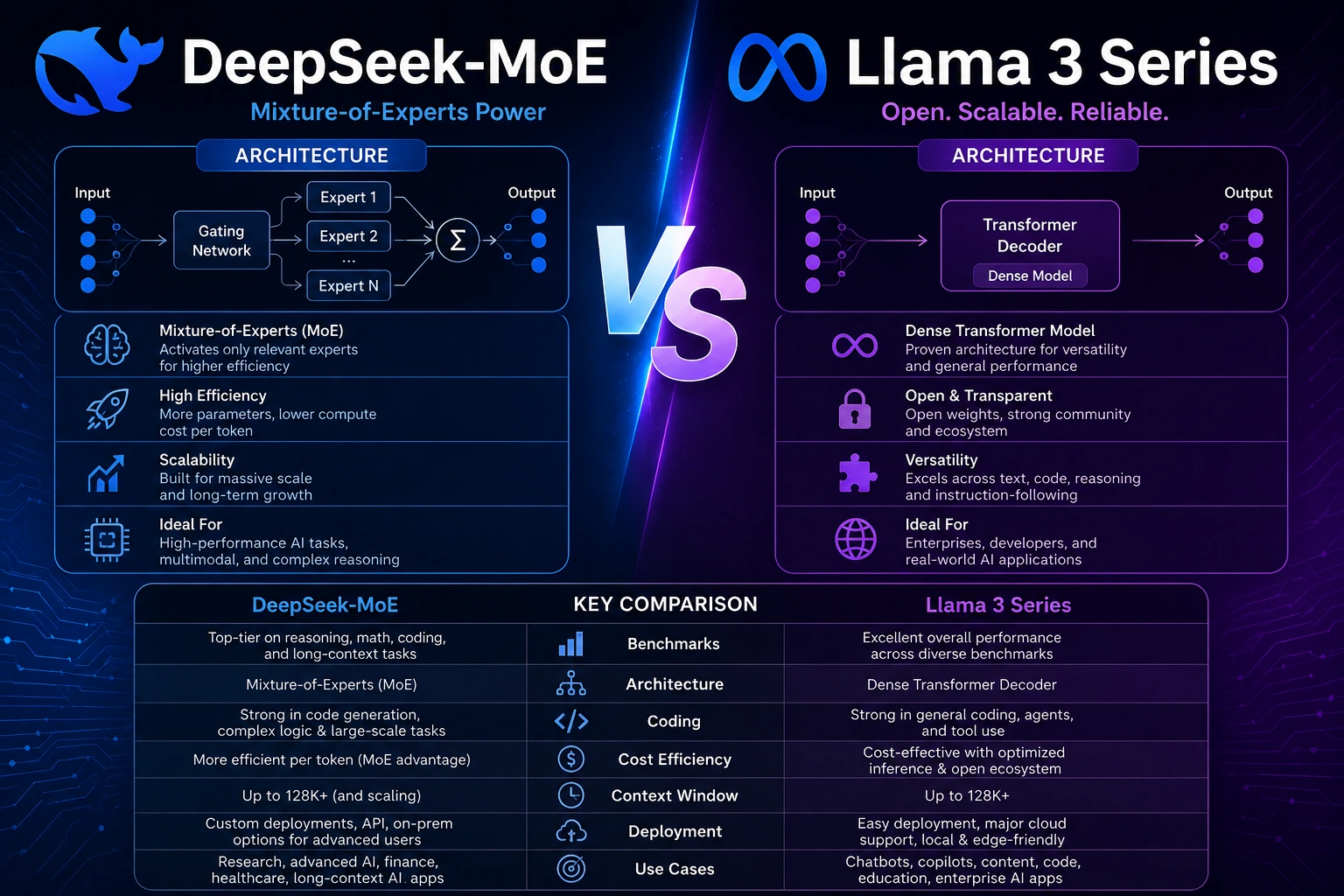
What Is DeepSeek-MoE?
DeepSeek-MoE refers to DeepSeek’s Mixture-of–Experts architecture family.
Unlike traditional dense models that activate the entire network for every token, DeepSeek activates only selected expert blocks during inference.
That means:
- Lower compute per token
- Better scaling efficiency
- Higher throughput potential
- Reduced operational cost
DeepSeek V3 became especially notable because it combines:
- 671B total parameters
- Only ~37B activated parameters per token
- Multi-Head Latent Attention (MLA)
- Auxiliary-loss-free expert balancing
This architecture made DeepSeek one of the strongest open-weight alternatives in modern AI.
What Is Llama 3 Series?
Llama 3 Series is Meta’s family of open-weight dense language models.
Dense means the model generally uses its full active network during inference.
Advantages include:
- Predictable latency
- Strong tooling ecosystem
- Easier compatibility
- Mature deployment support
Popular variants include:
- Llama 3 8B
- Llama 3 70B
- Llama 3.1 405B
Llama remains one of the most widely adopted foundations for enterprise fine-tuning.
DeepSeek-MoE VS Llama 3 Series: Quick Comparison
| Category | DeepSeek-MoE | Llama 3 Series |
| Architecture | Sparse MoE | Dense Transformer |
| Compute | Activated experts only | Full network |
| Cost Efficiency | Excellent | Moderate |
| Ecosystem | Growing rapidly | Extremely mature |
| Local Deployment | Strong with quantization | Excellent |
| Coding | Very strong | Strong |
| Enterprise Integration | Improving | Mature |
| Long Context | Optimized | Reliable |
| Fine-Tuning | More complex | Easier |
Winner: Depends on the objective.
Architecture Breakdown: Why This Comparison Actually Matters
Most competitor articles stop at parameter counts.
That misses the real story.
Dense Models
Every token flows through nearly all layers.
Benefits:
- Stable behavior
- Easier optimization
- Simpler serving
Trade-offs:
- Higher inference cost
- Larger memory usage
Mixture-of-Experts (DeepSeek)
Input tokens are routed to specialized experts.
Benefits:
- Better efficiency
- Lower active compute
- Strong scaling
Trade-offs:
- Routing complexity
- Deployment tuning
Think of it this way:
Dense → The entire company joins every meeting.
MoE → Only relevant teams attend.
Benchmark Results (2026 Perspective)
Benchmarks are directional—not the final truth.
| Benchmark | DeepSeek-MoE | Llama 3 |
| MMLU | Excellent | Excellent |
| BBH | Strong | Strong |
| Coding | Excellent | Strong |
| Long Reasoning | Excellent | Strong |
| General Chat | Strong | Excellent |
DeepSeek increasingly closes gaps while Reducing active compute.
But Llama remains extremely stable across workloads.
DeepSeek-MoE VS Llama 3 Coding Performance
For developers, benchmarks only matter if shipping speed improves.
DeepSeek Wins For
- Code generation
- Large repositories
- Cost-sensitive APIs
- Agent workflows
Llama Wins For
- Local inference
- Fine-tuning
- Existing tooling
- Enterprise compatibility
Developer recommendation:
Startup → DeepSeek
Enterprise → Llama
Reasoning & Math Performance
Reasoning performance depends on:
- Training objective
- Context utilization
- Routing quality
DeepSeek shows strong gains because MoE increases effective capacity.
Llama maintains consistency and fewer edge-case failures.

Speed & Cost Analysis
Cost became the biggest ranking factor in 2026.
DeepSeek
Pros:
- Lower active compute
- Better token economics
- Efficient scaling
Cons:
- More deployment tuning
Llama
Pros:
- Predictable serving
- Easier infra planning
Cons:
- Higher compute load
If your monthly Inference budget matters:
DeepSeek often wins.
Context Window Comparison
Long context is no longer optional.
DeepSeek advantages:
- KV optimization
- Efficient attention
Llama advantages:
- Stable long-sequence behavior
For:
Research → DeepSeek
Production chat → Llama
Which Model Is Better For Businesses?
Choose DeepSeek If:
- Budget matters
- API costs are high
- Teams process massive documents
Choose Llama If:
- Reliability matters
- The existing AI stack already exists
- You want faster deployment
Which Model Is Better For Developers?
Choose DeepSeek
If you:
- Build AI apps
- Optimize cloud spending
- Run coding workflows
Choose Llama
If you:
- Fine-tune models
- Need mature tooling
- Want broad community support
Pros & Cons
DeepSeek-MoE
Pros:
- Efficient
- Strong benchmarks
- Lower active compute
Cons:
- Operational complexity
- Routing overhead
Llama 3
Pros:
- Mature ecosystem
- Reliable
- Easier deployment
Cons:
- Higher inference cost
People Also Ask
A: For cost efficiency and scaling, often yes.
For ecosystem maturity and deployment simplicity, Llama remains stronger.
A: Usually more efficient per token but more complex operationally.
A: DeepSeek.
A: Llama generally offers simpler local deployment.
A: It depends on workload, budget, and deployment constraints.
Conclusion
The debate around DeepSeek-MoE VS Llama 3 Series is no longer about which model has more parameters—it is about which Architecture delivers better outcomes for your goals.
DeepSeek-MoE represents the next wave of efficient AI design. By activating only a subset of experts for each token, it pushes performance while reducing inference costs and improving scalability. That makes it especially attractive for startups, AI product teams, high-volume applications, and organizations focused on maximizing compute efficiency.
Llama 3 Series takes a different path. Its dense architecture, mature ecosystem, strong community support, and reliable deployment experience continue to make it one of the safest choices for developers and enterprises building production-grade AI systems.










