Introduction
Artificial intelligence is evolving faster than ever, and two models dominating developer discussions in 2026 are DeepSeek-MoE And Claude 3 Sonnet. While most AI comparisons focus only on benchmark scores, the real battle is happening in practical workflows: coding, AI agents, startup automation, enterprise deployment, and cost efficiency.
For developers, startups, SaaS founders, and European enterprises looking to scale AI affordably, choosing the right model can dramatically impact productivity and operational costs. DeepSeek-MoE has disrupted the AI industry with its Mixture-of-Experts (MoE) architecture and open-source advantages, while Claude 3 Sonnet continues to dominate enterprise workflows with strong reasoning, safety alignment, and long-context performance.
But which AI model is actually better for coding, content generation, self-hosting, AI agents, and real-world deployment?
In this detailed comparison, we will analyze:
- MoE vs dense transformer architecture
- Coding and debugging performance
- API pricing and inference economics
- Long-context handling
- Open-source vs proprietary AI
- Enterprise and startup use cases
- Benchmark performance
- AI agent workflows
- Security, privacy, and compliance
Whether you are an AI researcher in Germany, a SaaS startup founder in the UK, or a developer building AI agents in the Netherlands, this guide will help you choose the right model for your workflow.
Why This Comparison Matters in 2026
The AI market is shifting from “largest model wins” to “most efficient model wins.”
Traditional dense transformer models like Claude 3 Sonnet deliver excellent reasoning and alignment, but they are expensive to train and run at scale. Meanwhile, DeepSeek-MoE introduced a more cost-efficient approach using sparse activation through a Mixture-of-Experts architecture.
This matters because:
- AI infrastructure costs are exploding
- Startups need cheaper inference
- Developers want open-source flexibility
- Enterprises need privacy and governance
- AI agents require scalable token efficiency
As Europe increasingly emphasizes AI sovereignty and data compliance, open-weight models like DeepSeek are becoming highly attractive alternatives to proprietary systems.
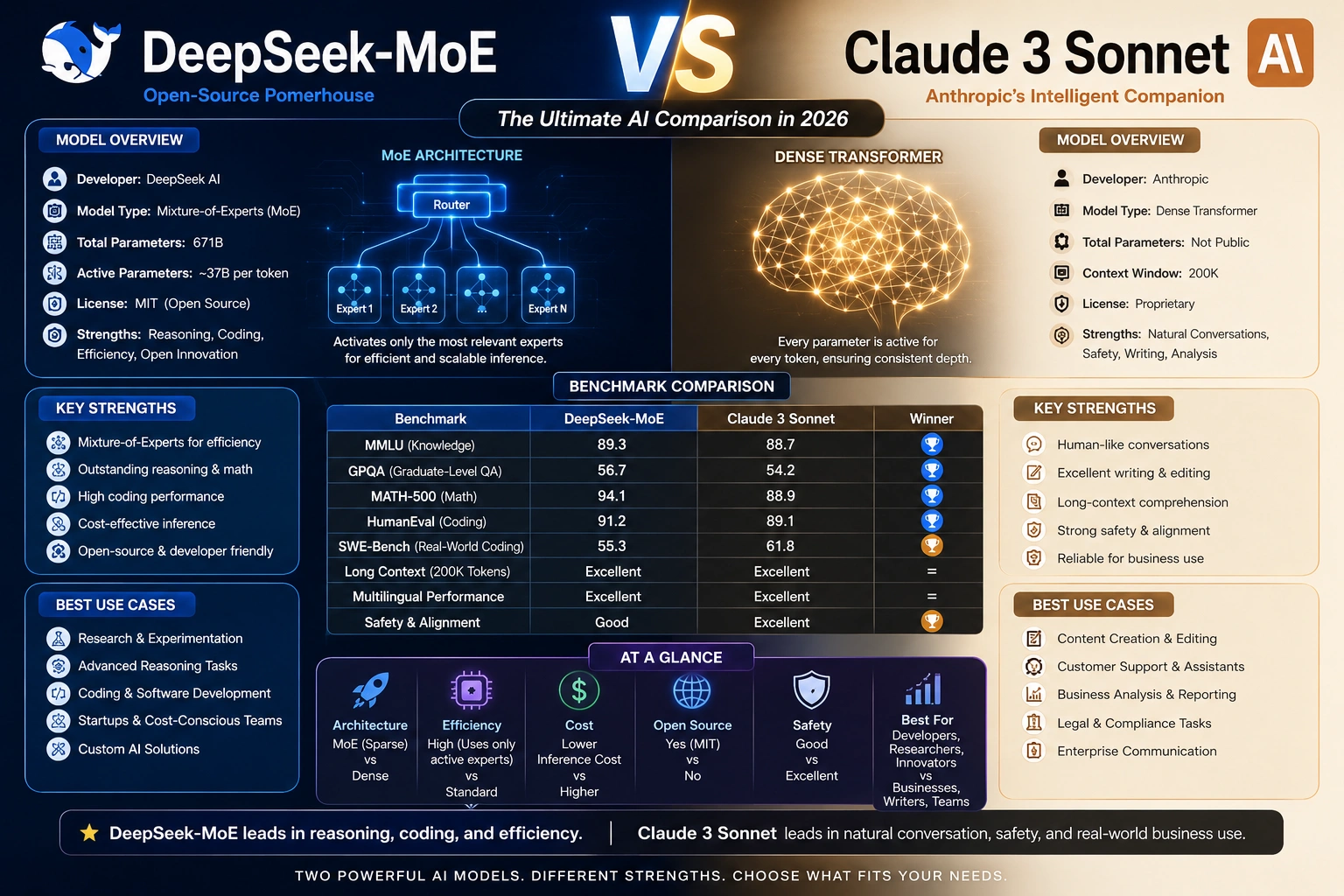
What Is DeepSeek-MoE?
Understanding DeepSeek’s MoE Architecture
DeepSeek-MoE is an advanced open-weight AI model designed around the Mixture-of-Experts (MoE) architecture.
Instead of activating the entire model for every token, DeepSeek activates only specific expert subnetworks.
This drastically improves:
- Inference efficiency
- GPU utilization
- Cost-per-token economics
- Scalability
- Training optimization
DeepSeek-V3 reportedly uses around 671B total parameters while activating only about 37B parameters per token.
That means users gain massive model intelligence without paying the full computational cost of a dense model.
Why DeepSeek Became Disruptive
DeepSeek gained attention because it challenged the idea that frontier AI must always be expensive.
Its biggest advantages include:
- Open-weight accessibility
- Exceptional coding performance
- Lower inference costs
- Strong benchmark efficiency
- Self-hosting potential
- Startup-friendly deployment economics
For European startups concerned about vendor lock-in and data governance, DeepSeek offers a compelling alternative.
What is a Claude 3 Sonnet?
Anthropic’s Enterprise-Focused AI Model
Claude 3 Sonnet is part of Anthropic’s Claude 3 family, designed primarily for:
- Enterprise AI workflows
- Safe reasoning
- Long-context analysis
- Business productivity
- Professional writing
- Regulated industries
Unlike DeepSeek’s MoE system, Claude uses a dense transformer architecture, where the full model participates during inference.
This improves:
- Consistency
- Alignment
- Structured outputs
- Complex reasoning quality
Claude 3 Sonnet is particularly popular among:
- Legal teams
- Financial analysts
- Enterprise developers
- Technical writers
- Research teams
Its 200k context window also makes it attractive for analyzing extremely large documents and repositories.
DeepSeek-MoE VS Claude 3 Sonnet: Quick Comparison Table
| Feature | DeepSeek-MoE | Claude 3 Sonnet |
| Architecture | Mixture-of-Experts (MoE) | Dense Transformer |
| Open Source | Yes (open-weight) | No |
| Best For | Developers & startups | Enterprises & writers |
| Context Window | Up to 128k | Up to 200k |
| Coding Performance | Excellent | Very strong |
| API Pricing | Extremely affordable | Higher pricing |
| Self-Hosting | Supported | Not supported |
| AI Agent Workflows | Excellent | Good |
| Alignment & Safety | Moderate | High |
| Enterprise Governance | Flexible | Strong |
| Writing Quality | Good | Excellent |
| GPU Efficiency | Exceptional | Lower efficiency |
| Fine-Tuning | Possible | Limited |
| Privacy Control | High | Vendor-controlled |
Architecture Comparison: MoE vs Dense Transformers
This is where the real battle happens.
How Mixture-of-Experts Works
MoE models divide the network into specialized expert groups.
Instead of activating all parameters simultaneously, only selected experts process each token.
Conceptually:
Inference Cost∝Activated Experts Only\text{Inference Cost} \propto \text{Activated Experts Only}Inference Cost∝Activated Experts Only
This creates major advantages:
- Lower compute costs
- Faster scaling
- Better token economics
- Reduced GPU load
- Improved deployment flexibility
Why Dense Transformers Are Different
Claude’s dense transformer architecture activates the full model every time.
Advantages include:
- Better consistency
- More stable reasoning
- Improved alignment
- Stronger enterprise safety
However, dense systems are generally:
- More expensive
- Less GPU-efficient
- Harder to scale economically
Which Architecture Wins?
DeepSeek-MoE Wins For:
- Cost efficiency
- AI infrastructure scaling
- Open-source deployment
- Startup experimentation
- AI research
Claude 3 Sonnet Wins For:
- Enterprise reliability
- Safety alignment
- Regulated workflows
- Long-form reasoning
- Professional content generation
Coding Performance Comparison
Developers are one of the biggest audiences searching for this keyword.
Frontend Development
DeepSeek performs extremely well in:
- React
- Next.js
- Tailwind CSS
- Vue
- TypeScript
It generates concise and efficient frontend code with fewer unnecessary abstractions.
Claude, however, often produces cleaner architecture explanations and better documentation.
Winner:
- DeepSeek for rapid coding
- Claude for maintainability
Backend Development
For backend workflows:
- DeepSeek excels at speed and scalability
- Claude excels at structured logic and readability
Claude performs particularly well in:
- API documentation
- Enterprise architecture
- Secure workflows
- Database reasoning
DeepSeek performs strongly in:
- Python automation
- DevOps scripting
- AI backend pipelines
- Large-scale code generation
Debugging & Refactoring
DeepSeek is highly effective for:
- PR reviews
- Large codebase scanning
- Bug localization
- Fast debugging
Claude is better for:
- Explaining bugs clearly
- Producing safer fixes
- Maintaining coding standards
AI Agent Workflows
This is an area competitors rarely discuss.
AI agents require:
- Long iterative loops
- Tool usage
- Context retention
- Token efficiency
- Fast inference
DeepSeek’s lower cost structure makes it extremely attractive for:
- Autonomous coding agents
- Multi-agent systems
- AI copilots
- Research automation
Claude performs well in agent orchestration but becomes expensive at scale.
Content Writing & Creativity Comparison
Blog Writing
Claude 3 Sonnet generally produces:
- Better tone consistency
- More natural transitions
- Higher-quality business writing
- Cleaner readability
DeepSeek generates content faster but may require more editing.
SEO Content Creation
For SEO workflows:
Claude Strengths
- Better structure
- More polished introductions
- Strong informational flow
- Safer outputs
DeepSeek Strengths
- Faster generation
- Lower API cost
- High-volume content scaling
- Bulk automation
For agencies running thousands of AI-assisted articles, DeepSeek can dramatically reduce operational costs.
Marketing & Email Copy
Claude usually wins in:
- Persuasive copy
- Brand-safe tone
- Professional communication
- Enterprise messaging
DeepSeek is still highly capable but may require additional refinement.
Benchmark Comparison
Most articles stop here — but benchmarks only tell part of the story.
Coding Benchmarks
DeepSeek performs exceptionally well in:
- HumanEval
- SWE Bench
- Code generation tasks
- Repository understanding
Claude performs strongly in:
- Structured reasoning
- Multi-step planning
- Long-context comprehension
Reasoning Benchmarks
Both models perform impressively in:
- MMLU
- GPQA
- Mathematical reasoning
- Tool usage
However, benchmark dominance changes frequently as models update.
The more important question is:
Which model delivers better real-world productivity per dollar spent?
That is where DeepSeek becomes extremely competitive.
Pricing & API Cost Comparison
This is one of the biggest differences between the two models.
Why AI Infrastructure Costs Matter
Many companies underestimate how expensive AI inference becomes at scale.
For AI startups processing millions of tokens daily, pricing differences become massive operational expenses.
DeepSeek Pricing Advantages
DeepSeek is widely recognized for:
- Lower API pricing
- Better token efficiency
- Reduced GPU costs
- Affordable scaling
This makes it ideal for:
- AI startups
- SaaS products
- Automation systems
- AI agents
- Research projects
Claude 3 Sonnet Pricing
Claude remains more expensive but offers:
- Enterprise support
- Stability
- Advanced alignment
- Long-context capabilities
Large enterprises may justify the cost due to compliance and governance requirements.

Open Source vs Proprietary AI
Why Open-Source AI Is Growing
Europe is increasingly emphasizing:
- Data sovereignty
- AI independence
- Local deployment
- GDPR-friendly workflows
DeepSeek’s open-weight accessibility aligns strongly with this trend.
DeepSeek Open-Source Advantages
Benefits include:
- Self-hosting
- Custom fine-tuning
- Infrastructure control
- Reduced vendor lock-in
- Local deployment
- Transparency
This is especially important for:
- German enterprises
- EU AI startups
- Privacy-focused organizations
Claude’s Proprietary Model
Claude remains closed-source.
Advantages include:
- Better alignment
- Managed infrastructure
- Easier deployment
- Enterprise support
But disadvantages include:
- Vendor dependence
- Limited customization
- No self-hosting
- Higher long-term costs
Long Context Performance
Claude 3 Sonnet Context Window
Claude supports up to:
- 200k context
This is excellent for:
- Large repositories
- Research analysis
- Long legal documents
- Multi-file reasoning
DeepSeek Context Performance
DeepSeek commonly supports:
- Up to 128k context
It performs extremely well in:
- Codebase analysis
- Multi-file debugging
- AI agents
- Technical workflows
However, Claude generally maintains stronger coherence in ultra-long contexts.
DeepSeek-MoE VS Claude 3 Sonnet for Different Users
| User Type | Best Choice |
| Developers | DeepSeek |
| Enterprises | Claude 3 Sonnet |
| Startups | DeepSeek |
| Writers | Claude 3 Sonnet |
| AI Researchers | DeepSeek |
| Compliance Teams | Claude |
| Self-Hosting Users | DeepSeek |
| AI Agent Builders | DeepSeek |
| Long-Document Analysis | Claude |
Real-World Use Cases
SaaS Startups
DeepSeek is ideal for:
- Affordable inference
- AI copilots
- Startup automation
- Customer support bots
Its economics make scaling far easier.
Enterprise Workflows
Claude shines in:
- Legal research
- Financial analysis
- Corporate knowledge systems
- Internal documentation
Its alignment-focused design reduces risky outputs.
AI Coding Assistants
DeepSeek performs impressively for:
- GitHub workflows
- Code reviews
- Large-scale automation
- Autonomous coding systems
This is one reason developers frequently discuss it in AI engineering communities.
Security, Privacy & Compliance
DeepSeek Security Considerations
Advantages:
- Self-hosting control
- Local deployment
- Infrastructure flexibility
Risks:
- Requires internal security expertise
- Open-source governance complexity
- Potential compliance burden
Claude Enterprise Security
Claude offers:
- Managed infrastructure
- Enterprise agreements
- Centralized governance
- Strong safety alignment
This appeals to regulated sectors across Europe.
Pros & Cons
DeepSeek-MoE Pros
- Extremely affordable
- Open-weight accessibility
- Excellent coding performance
- Strong AI agent support
- Efficient MoE architecture
- Self-hosting support
- Great for startups
DeepSeek-MoE Cons
- Less enterprise polish
- Alignment can vary
- Requires technical deployment expertise
- Weaker writing quality than Claude
Claude 3 Sonnet Pros
- Excellent reasoning
- Strong writing quality
- Enterprise-ready
- Superior long-context handling
- Better alignment and safety
- Clean structured outputs
Claude 3 Sonnet Cons
- More expensive
- Closed-source
- No self-hosting
- Vendor lock-in risks
How to Use These AI Models Effectively
Best Practices for DeepSeek
- Use for coding-heavy workflows
- Deploy for AI agents
- Optimize startup automation
- Fine-tune for custom tasks
- Self-host for privacy-sensitive projects
Best Practices for Claude
- Use for enterprise reasoning
- Generate business content
- Analyze large documents
- Handle compliance-heavy workflows
- Build structured research pipelines
Europe-Focused AI Adoption Trends
European companies are increasingly prioritizing:
- GDPR-compliant AI
- Infrastructure transparency
- AI sovereignty
- Open-source ecosystems
This creates a major opportunity for DeepSeek adoption across:
- Germany
- France
- Netherlands
- Sweden
- Switzerland
However, enterprise-heavy industries in the UK and finance sectors still heavily favor Claude for governance and safety.
Future of MoE AI Models
Mixture-of-Experts architecture may define the future of scalable AI.
The industry is rapidly moving toward:
- Sparse activation
- Lower inference costs
- Specialized expert routing
- AI infrastructure optimization
- Energy-efficient AI systems
Conceptually:
Future AI→Higher Intelligence with Lower Compute\text{Future AI} \rightarrow \text{Higher Intelligence with Lower Compute}Future AI→Higher Intelligence with Lower Compute
DeepSeek represents one of the strongest demonstrations of this transition.
People Also Ask
A: It depends on your use case. DeepSeek is often better for coding, AI agents, self-hosting, and affordability, while Claude 3 Sonnet is stronger for enterprise reasoning, writing quality, and long-context analysis.
A: Mixture-of-Experts (MoE) is an AI architecture where only selected expert subnetworks activate during inference. This improves efficiency and reduces computational costs compared to dense transformer models.
A: DeepSeek is widely considered one of the best AI models for coding workflows, especially for debugging, repository analysis, and AI agent systems.
A: DeepSeek provides open-weight access, allowing developers to self-host and customize deployments more easily than proprietary models like Claude.
A: DeepSeek is generally far cheaper than Claude 3 Sonnet for API usage and large-scale inference workloads.
Conclusion
DeepSeek-MoE and Claude 3 Sonnet represent two very different visions for the future of AI.
DeepSeek is redefining AI economics with its Mixture-of-Experts architecture, open-weight flexibility, and Exceptional cost efficiency. For developers, startups, AI researchers, and autonomous agent builders, it offers one of the best value propositions in the market today.
Claude 3 Sonnet, on the other hand, remains one of the strongest enterprise AI systems available. Its long-context reasoning, writing quality, alignment, and professional reliability make it highly attractive for businesses, legal teams, research organizations, and enterprise productivity workflows.
If your priority is:
- Affordable scaling → Choose DeepSeek
- Enterprise safety → Choose Claude
- Self-hosting → Choose DeepSeek
- Professional writing → Choose Claude
- AI agents → Choose DeepSeek
- Long-context analysis → Choose Claude
The most important takeaway is this:
The future of AI is no longer just about intelligence. It is about cost-efficient intelligence at scale.










